Service level objectives (SLO) are standard way of defining the expectations of applications/systems (see SLA vs SLO vs SLI). One standard example of SLO is uptime/availability of an application/system. Simply, put it is % of time the service or application responds with a valid response.
It is also a common practice in large organizations for a SRE team to keep track of SLOs of critical systems and gateway services reporting them to leadership in frequent cadence.
But like any tool, SLO’s also have a motivation and a purpose. Without careful considerations these employing seemingly well intended policies can become a vanity metric and cause unintended consequences. In this post, I take one such situation I encountered in past and provide a simple framework that could help avoid these traps.
4 9’s Availability
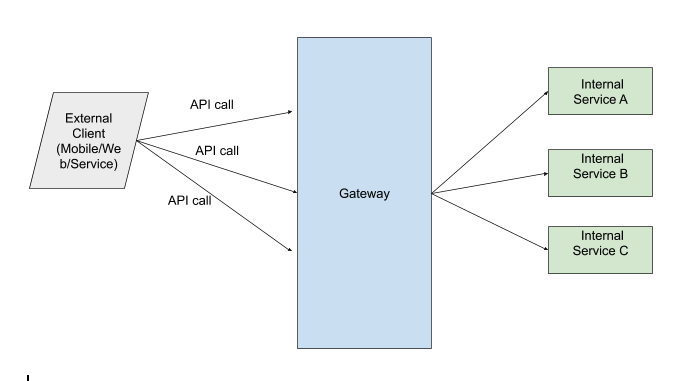
Simplified System Architecture of a Company
Consider above example which is a common architecture of a company. Usually a gateway service fronts all client/external calls and routes them to internal services. It is also common practice in some companies for a central SRE team to some company level tracks SLO at this gateway level (Note: individual teams still measure their own services’ SLOs).
Today, with commoditized hardware, databases, evolution of container system etc, it has become a common expectation to expect a high uptime of 4 9’s(jargon for 99.99% availability). Simple way this is usually measured is % of Success (2xx in http protocol) responses your application sends with respect to total number of requests. This has almost become a vanity metric for engineering organization. Let us see two classed of problem caused without putting proper thought while defining them.
Lazy Policy Effect
If all you measure is availability across all endpoints as vanity metric, then it is possible that 1 particular endpoint has dominant share of traffic to your service. But does this traffic share reflect the importance of endpoint?
Ex: Let us consider two endpoints.
Logging endpoint used to capture logs on the device and forward them to backend for analytics purpose.
Sign-in endpoint used to authenticate user’s session.
It is easy to see how first endpoint can have more traffic and can hide the availability. As SRE team the numbers/SLOs always look good week-over-week if first endpoint is stable.
I call this lazy policy effect. It happens, because at the time of defining SLO’s, it is possible that authors of this policy never asked few critical questions.
What is the purpose of tracking this SLO? Most often the answer will be – “We need to ensure we are` providing best experience to customers”. Which leads to question #2
Is this metric truly achieving this purpose? It is clear at this point to see that not all endpoints directly contribute to customer experience. So you probably need a policy which segments endpoints by category (customer facing vs operational etc) and only measures SLOs for relevant ones.
Bad Incentive Effect
Not let see another consequence of these blanket policies.
Let us say 1 of the endpoint’s purpose is to collect sensor logs mobile device periodically. This is most likely a background process which does not interfere with consumer experience on device. In this case, it is easy to see how certain level of failures is acceptable for this endpoint. We can have the device retry on failures or even afford to miss some logs.
But this team unfortunately has to abide by the above 4 9’s policy set by SRE. Otherwise they will contribute to drop in organizational level SLO and will be called into next leadership review to provide an analysis. No matter how well intended and blameless these reviews are, most teams will try to avoid being called into these reviews. There are various “clever” ways you can do that.
One of them, is add multiple retries between gateway -> dowstream service. Or increase timeout duration for calls from gateway -> dowstream service etc. You get the idea.
These will certainly reduce 5xxs (and improve availability SLO). But unnecessarily increased latencies or caused these logging apis take up more resources on the gateway host. This could increase latencies for other “customer” endpoints. Lot of times these are even hard to notice.
Even though organization has defined these policies for better customer experience, they actually degraded customer experience. This might even go unnoticed because the availability SLO is always met.
Aspects to Consider
When defining such engineering policies in organization or team it is important to ask following questions.
Purpose Of THE SPECIFIC SLO
What is the purpose of tracking this SLO?
Is this metric truly achieving this purpose and in what situations will this metric not service this purpose?
Second ORDER CONSEQUENCES
What does it mean for engineering teams to adhere to this policy/SLO?
What feedback mechanism from teams do we need to put in place (so that we can adapt these policies and not incentivize teams to put work arounds)? Every policy needs to adaptable. Especially policies which demand large organizational cost to adhere to them.
In this blog post, I will go through some patterns for maintaining consistency between cache and database when using application level cache. Specifically I will focus on cache-aside/look-aside-cache pattern.
Application Cache: What and Why?
Cache is a temporary storage that is typically has smaller size and provides faster access time to data.
Application level caching is a common pattern in modern microservices architecture. In this pattern a cache is used alongside the underlying database. Frequently queried data is retrieved from cache as opposed to a database. There are multiple advantages for maintaining a cache. Some of which include:
Improving read latency: Since one of the common responsibilities of underlying storage is durability, often data is stored in file system. This can reduce performance of read. Popular caches like memcached and redis store data in memory enabling faster look up times.
Some databases also provide cache for faster lookup for frequent queries. For example, mysql provides query cache. But there are still reasons to not use the underlying storage as cache.
You don’t want to overload your underlying storage for some hot key reads. Ex: In a Social media platform a famous celebrity’s post might have more frequent access and create excess load to one particular partition.
There are more than 1 query patterns to underlying data. So one data model which is used by underlying storage does not always fit your query needs.
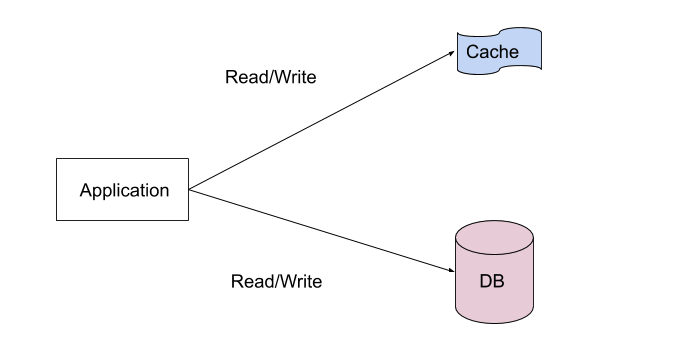
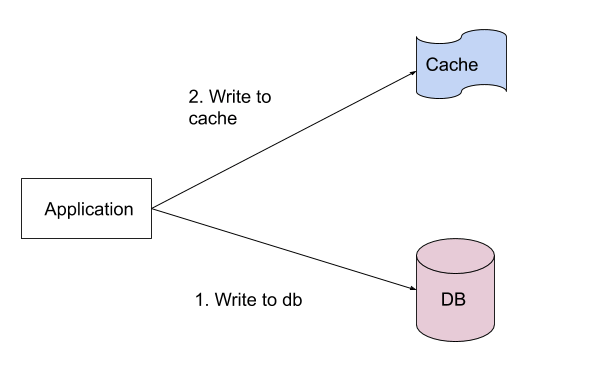
Following diagram illustrates a simple cache-aside architecture.
FIGURE 1
Consistency Models
There are different patterns you can use to hydrate and evict cache. Each gives us different trade offs and guarantees in terms of consistency between cache and underlying storage. These trade offs emerge primarily from behavior under failures/ network partitions and concurrent access.
One way to understand these tradeoffs is to think about cache as an extension to our database and use the Consistency Models from distributed system literature. I will go over couple of them which are relevant to this blog.
Strict Consistency
Sequential Consistency
Sample System
Let us assume our application has 2 nodes, a cache and underlying database.
We have one item called counter in our database whose values are numbers starting from 1. Let the initial state of the counter is 0. Some other symbols we will use going forward:
N1 : Application Node 1
N2 : Application Node 2
W(c)=1: represents write operation on counter to value 1
R(c)=1 : indicates read operation returned value 1
Strict Consistency
This is strongest form of consistency model. Under this model:
All operations read/write should follow wall clock order.
Every process (in our case cache and storage) should see the result on an entity (in our case counter) at any given time. In other words, no stale reads.
I am going to illustrate this with two examples.
FIGURE 2
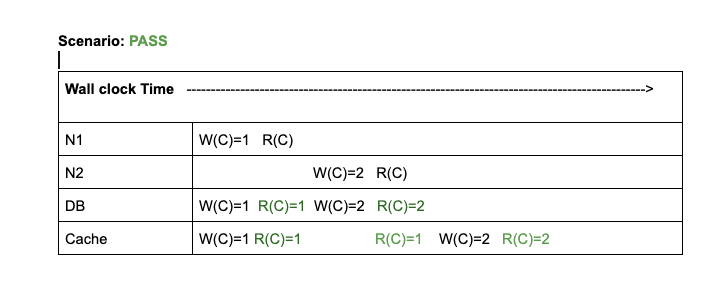
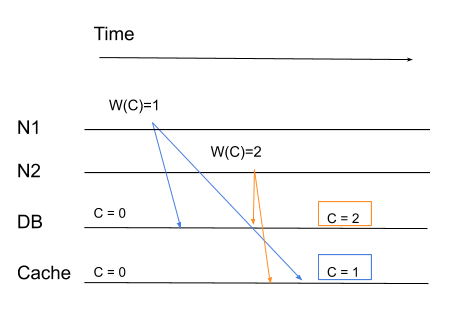
At some time t0 N1 updated the counter to 1
Immediately when a read operation was performed, both DB and Cache were able to retrieve the updated value
At time tX (X > 0), N1 updated the counter to 2
Immediately when a read operation was performed, both DB and Cache were able to retrieve the updated value
This system satisfied both our criteria. Cache captured the order writes correctly and also there was no lag in capturing in this update.
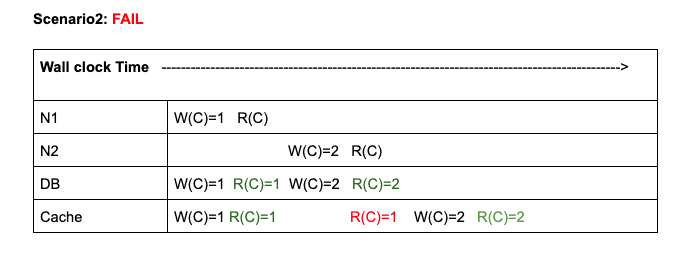
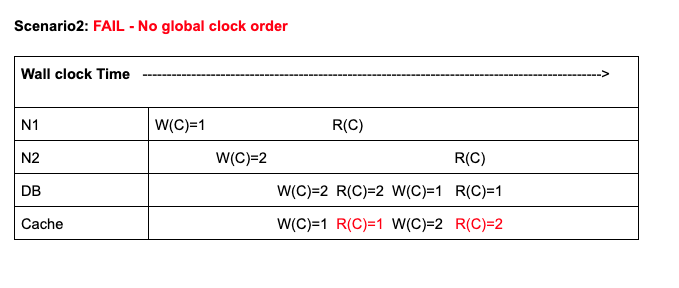
Scenario 2
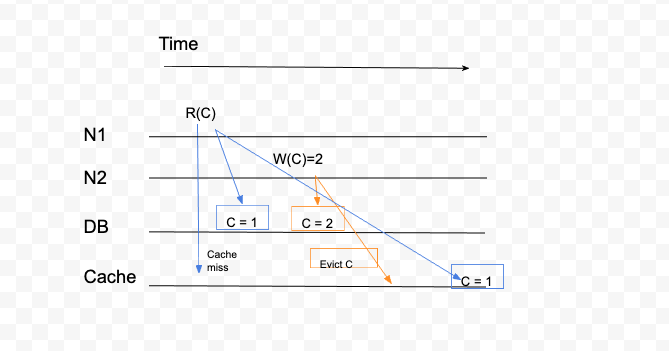
FIGURE 3: Stale reads in cache caused failure of Strict Consistency.
In this example, you can see that immediately after updating counter to 2, cache returned a stale result. This because the write operation arrived at Cache little late. So, result returned from DB and Cache do not agree with each other. Eventually at a later time, the read operation on cache returned correct result. So, violated freshness condition and hence its not Strictly Consistent.
Scenario 3
FIGURE 4: Out of order writes caused failure of Strict Consistency.
In this example, though cache and DB agree on values all the time, both of them got the writes out of order. W(C)=1 was issued before W(C)=2. But by the times write reached cache and storage, order got swapped because of network delays.
Note: Strict consistency needs wall clock ordering which is very difficult. This means we need clock sync between application, database and cache.
Sequential Consistency
Under this model
All read/write ops were executed in some global ordering (not necessarily wall clock but every one needs to agree on the order)
Does not enforce any latency requirements.
For our application cache topic, the main concern is #2. This is where scenario 2 in sequential consistency.
FIGURE 5
Eventually if the values converge and order of operations is same across both, then we can say sequential consistency is preserved.
Another failure scenario is when cache and db do not agree on same order of operations.
FIGURE 6
Here, both DB and cache do not agree on same ordering of events. So this breaks condition #1 above.
This sequence matters if you are using cache for not just storing last value of Counter but have to show the history of updates to user. In that case even if background process updates latest value in cache to be in sync with db, the history of changes will not reflect the same order as DB.
Cache Update Patterns
Now that we looked at some consistency models that are relevant to our topic, let us shift attention back towards patterns for updating the cache in a cache-aside/look-aside architecture.
Update on Write
In this approach, application updates cache along with database for every write operation.
FIGURE 7
So when a new write operation is issued to the application, it first writes to DB and then writes to cache..
This seemingly simple approach has few downsides in failure modes and concurrent write situations.
Failure Modes
FIGURE 8
Consider the above scenario.
At time t=0, both DB and cache have a value 0 for counter C
At time t=1, application issued a successful update to DB for counter C to 1.
Application then tried to update cache, but this write fails. As result the value in cache remains stale
This clearly breaks our Sequential Consistency model as our cache no longer agrees with DB. Worst yet, because we are updating cache only on a write operation, our cache will continue to respond with stale value till another write happens. Depending on your application this may or may not be a problem
For example, if this cache is used in social media posts to store the last response to a post, then its okay if application is sending a slightly stale response for a while.
But on contrary if you are using this in an auction application, where cache is used to check latest bid to validate if the next bid is bigger; then you will inadvertently accept a bid when you are supposed to reject the bid.
One way you can mitigate this is by using 2 Phased Commit (2PC) with your application acting as coordinator.
Even then its not fully failure-proof for various reasons like:
You need support from both the DB and Cache to perform Prepare and Commit Steps
Even then you can still have cache fail on Commit phase
Or What if your application node dies after issuing Commit to DB and before issuing to Cache?
CONCURRENT WRITE ISSUE
Apart from failure modes we saw earlier, there are another set of issues this method encounters when two nodes are concurrently performing writes. Figure 9 below illustrates this.
FIGURE 9
In this case, two nodes N1 and N2 and updating the value of Counter C. But due to network delay, the write operations to cache and DB are not in same order which causes divergence in values in cache vs DB.
There are couple of ways you can solve for this.
Using Locks
If the underlying DB and Cache both support locking, then we can leverage this to solve the above issue. At the beginning of the write operation, application node will acquire lock for Counter C from both DB and cache and release the lock after write succeeds.
Since lock is acquired first by N1 (who gets first request to write in our example), it ensures that N2’s write doesn’t get written to cache first.
However, locks can cause performance bottlenecks and hence should be used carefully. Not all applications can tolerate that performance hit.
Using Compare and Set (CAS)
Some cache providers have CAS capabilities (ex: memcache CAS command). Before writing to cache, application can read the value for the key. In response, along with value for the key, cache also provides another incremental token (which gets updated on every write). Application will then issue a CAS command with both new value and token. Under the hood, cache will only accept the value, if the token matches the token for the key in cache. If another write to cache happened between application reading and writing, then this token will chance in the cache and hence write will be rejected.
In our example in Figure 9, when cache gets the write from Node N1, it would recognize that value has already been updated since N1 has performed a read, and hence would reject the stale write.
This is arguably less expensive than lock solution above, since you dont need locks. But this is still an expensive operation and should be used only if your application requires this consistency (ex: acution bid example above).
Evict on Write & Update on Read
In this approach, on every write operation, application updates the DB and evicts the key from cache. So on next read operation, when there is a cache miss application will fetch the value from DB and updates cache.
This approach definitely solves concurrent write issue we saw in Figure 9. The reason is, both write operations to cache will be to evict cache. So, it does not matter which order they come in, because end result will be same.
So does that mean our problems are solved? Not really. Because this approach introduces another kind of concurrency issues which can be illustrated with Figure 10 below.
FIGURE 10
What happened here?
N1 tries to read key C from cache and encounters a cache miss.
So N1 reads value from DB and issues a update to C.
In the meanwhile, N2 updated C in DB and invalidate Cache.
Due to network latency, update to C from step #2 reaches cache now. Which means cache will have a value C = 1. This causes a divergence between DB and cache.
I personally, do not see many benefits of this approach over the previous approach. Arguably, you can delay your evict operation after write so that all pending read-updates to cache finish. But this is not a very deterministic, since you do not know how long network delays can be.
This leads us to a next pattern “Update via Change Data Capture” which solves concurrency and fault tolerance issues very well.
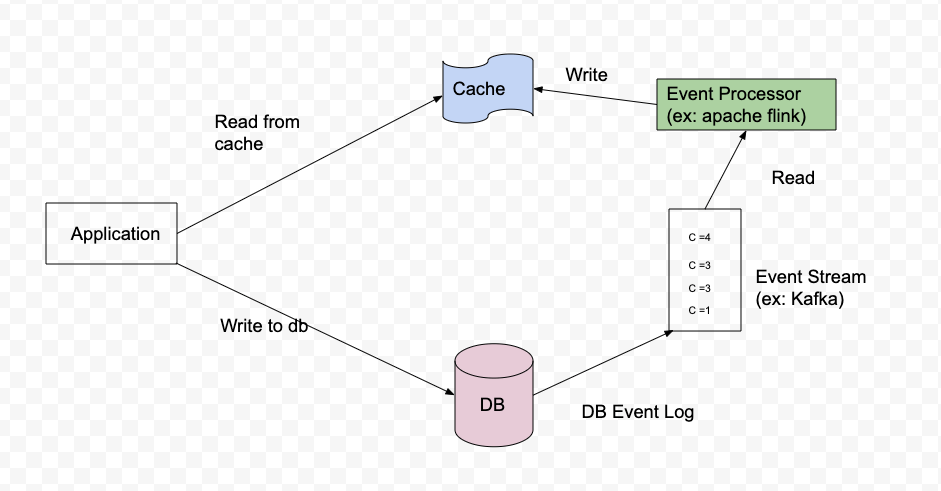
Update via Change Data Capture
Change data capture is a mechanism where changes to DB are logged into a message stream. A separate event processing system, consumes these messages and updates the cache accordingly. This concept is explained in depth here by Martin Kleppmann.
This is a slightly complicated setup that requires:
Database which logs all updates in sequence to a event log (mysql bin log)
Event streaming platform like kafka which provides fault tolerance and at-least once delivery of messages along with retaining order of messages.
Stream processor system (like Apache flink) which can consumer these messages in real time and provide exactly-once semantics.
Here is a diagram illustrating this architecture
Figure 11
This approach has few Pros and Cons as discussed below.
Pros
This solves the concurrency issues discussed (Figure 9 and Figure 10) in the approaches above. This is because we have a separate system that is sequentially updating the cache, which means there are no concurrent writes happening in cache. Concurrent writes only happen to DB. Once database resolves the order of writes, our stream processing system will replay those events to the cache in the same order.
Provides Sequential Consistency. Since we rely on system like Apache Flink and Apache kafka which provide fault tolerance guarantees, we will not a miss an update to the cache.
Cons
Maintenance and Operation Overhead: As we can see from diagram, this requires a complicated setup. This brings operational and maintenance challenges. So unless, these concurrency guarantees are required for this system, the cost of setup and maintenance might not be justified
Delayed updates: Even though Apache kafka, Apache flink provide high throughput and low latency, it is still possible that updates to your cache might be slightly delayed. In steady state, this will likely be order of sub seconds or seconds. Depending on the application it may or may not be acceptable to have that delay as it will cause stale reads. So we need to consider these cases carefully.
Failure in event processing: If stream processor system goes down and takes a while to bring it back up, then cache will be stuck with stale data for that duration. We can avoid these stale reads by force restarting/evicting cache to make application read from DB . Also, on restart event processor might take a while to catchup to latest update. It can cause stale reads during this catching up period. You can avoid these stale reads by having stream processor start from latest update (if history is not needed in cache).
Summary
In this blog we looked at different patterns (Update on Write, Evict on Write & Update on Read, Update via Change Data Capture) which can be used to update cache in a cache-aside architecture. We looked at behavior of each of these patterns during a failure/network-partition and concurrent updates in distributed application. It is clear from these tradeoffs that there is no free lunch. As a developer, the choice must be informed by Consistency requirements of your end user application, maintenance & operational overhead.
Please leave your thoughts and comments below. I look forward to learning from your experience.
References
In writing this blog I used some of my experience and information from the following resources.